The Problem of the Origin of Life
1953 was an exciting year for biology. Not only did James Watson and Francis Crick work out the double-helix structure of DNA, but in the same year Stanley Miller published the results of his famous ‘primeval soup’ experiments in which he produced some amino acids by passing an electric spark through a mixture of water vapour, hydrogen, methane and ammonia. So, just as basic genetic mechanisms were being understood, came the first clear evidence that organic compounds could arise from abiotic sources – prompting enthusiastic speculations about the origin of life.
It was recognised that amino acids are only rudimentary building blocks, but biologists were sure the rest would follow. They were confident that the origin of life could be accounted for solely in terms of physics and chemistry, and that it was just a matter of time before the whole story, from prebiology to simple organisms and then to the full array of present-day life, would be unravelled. According to Miller, biologists of the 1950s expected to be able to explain the origin of life within 25 years[2].
But it didn’t work out that way. In fact 40 years after his early soup experiments, Miller admitted that solving the riddle of the origin of life had turned out to be much more difficult than he or anyone else had anticipated (ibid, p138). And now, after nearly 60 years, the problem of the origin of life is just as insoluble, if not more so as we have explored various possible routes and found them to be dead ends. A clear indication that the problem is proving such an obstacle is that there is no generally accepted coherent theory for the origin of life; different groups of investigators have their preferred options, and point out the failings of others’.
So why has the bubble burst?
The problem
The problem is that we have come to realise that even the simplest forms of life are complex on at least two different levels.
1. The interdependence of biological macromolecules
First, life depends on the interdependence of many different biological macromolecules, typified by the replication of DNA and the synthesis of proteins.
-
Despite the conceptual simplicity with which double stranded DNA can duplicate - each strand acting as a template to build the other - DNA cannot copy itself, but requires many proteins (mostly enzymes, but also others) to carry out the process (Figure 1). (A summary of the process can be found in textbooks of molecular biology, or at many sites on the internet, such as en.wikipedia.org/wiki/DNA_replication.)
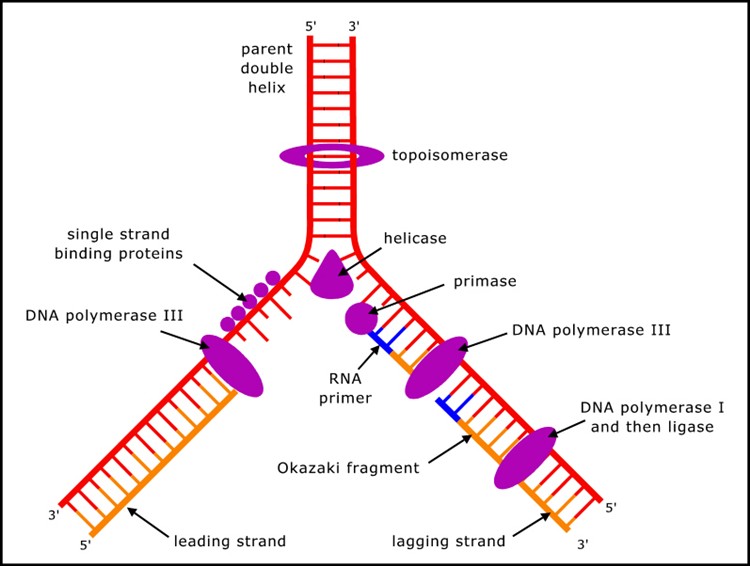
Figure 1. Key components in DNA replication.
-
But neither can proteins replicate themselves: that requires DNA to specify the sequences of amino acids in the proteins, and various RNAs (also coded by DNA) that are part of the molecular machinery used to implement the genetic code (Figure 2). The major types of RNA are messenger RNA (mRNA) which carries a copy of the relevant gene; transfer RNA (tRNA) which mediates the genetic code; and ribosomal RNA (rRNA) which is a key component of ribosomes where the protein synthesis actually takes place. (A summary of protein synthesis can be found at en.wikipedia.org/wiki/Protein_biosynthesis.)
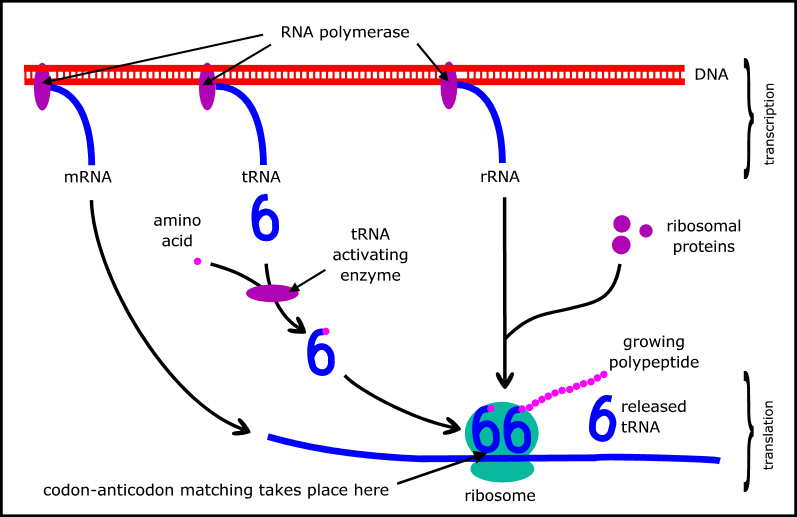
Figure 2. Schematic of protein synthesis.
As Karl Popper said, “What makes the origin of life and the genetic code a disturbing riddle is this: the code cannot be translated except by using certain products of its translation”[4].
2. The individual macromolecules are complex
But the complex interaction of biological macromolecules is only one aspect of the problem facing the origin of life. What compounds the enigma is that the individual macromolecular components are themselves complex, in the sense that their sequences - of ribonucleotides in the case of RNA, or amino acids for proteins - are very specific.
The linear amino acid sequence of a protein is specific because it must (a) be able to fold into a discrete 3-dimensional structure, and (b) have the right amino acids in the right positions in the linear sequence so that, when folded, they are in exactly the right positions in relation to each other to form the active site(s) of the protein.
(And similar considerations apply to RNAs.)
Sequences which meet these criteria are exceedingly rare compared with the astronomical number of possible sequences of a suitable length. For example Douglas Axe has estimated that only 1 in about 1074 possible sequences will have biological function [1]. So it is totally unrealistic to think that such sequences could have arisen by chance. How much less a suite of mutually dependent macromolecules?
If the components themselves were not so improbable then it might be realistic to think that a complex combination of components could arise by chance; but the extreme improbability of the individual components is such that they are very unlikely to arise individually, and hence there is no chance whatever of an interdependent system.
Where even just two macromolecules are required to perform a function, then it would be necessary for both components to arise together: Because natural selection does not have foresight: if one component arises alone it will not be retained for potential future usefulness (when the second component is available), but will almost certainly degrade by mutation. And, it should be noted, if the probability of getting one component is 1 in 1074 then the probability of getting two together is 1 in 10148 (not 1 in 2 x 1074); and so on for multi-component systems. This is why the obligatory mutual dependence of many macromolecules in even basic biological systems completely defies any hope of an evolutionary origin.
So, in summary, the crux of the problem is that even a basic biological replicating system requires (a) several macromolecules with complementary functions with (b) each having a highly improbable sequence. And this combination of complexities presents an insurmountable challenge to a naturalistic origin of life.
Some false hopes
In a short article such as this I cannot deal fully with the various possibilities that have been pursued to try to circumvent the problem. But I will give an indication of the fundamental difficulties, and expose some key flaws and uncritical even wishful thinking in putative scenarios - which, unfortunately, are usually completely overlooked in popular accounts of the origin of life.
Abiotic origin of monomers - but what’s needed are polymers
First it must be emphasised that producing monomers - amino acids or the bases found in nucleic acids (DNA and RNA) - in prebiotic soup experiments, so often portrayed as proof that life could have arisen naturally, is nothing of the sort. Because what is needed are polymers of these; and not just any polymer, but those with a sequence that confers useful biological activity; and in the context of the origin of life, that activity needs to be self-replicating, or at least contributing to a replicating system.
Yet the formation of polymers in itself (regardless of the possible usefulness of their sequence) presents several problems which for the sake of clarity I shall discuss first in the context of amino acids and proteins, and comment later on the applicability of these comments to nucleotides and nucleic acids.
Abiotically, it requires many hours in hot mineral acid to hydrolyse peptide bonds (which is why proteins are so stable, and suitable for building biological tissues), but biologically this reaction is achieved readily with appropriate enzymes (e.g. the digestive enzyme trypsin).
So the point I am making here is that the conditions required to make and break peptide bonds are very different. That is, prebiotic scenarios would require transfer of the nascent polypeptides from one sort of environment to a chemically very different one, or some means of radically changing the conditions in the same environment (but without flushing out the polypeptides).
Whilst it is not too difficult to envisage possible situations (e.g. using ocean vents) that might have given the required different or changing conditions, at the very least this means that the volume where such ‘experiments’ might have taken place would have been severely limited - we certainly cannot envisage oceans of productive primeval soup.
As indicated above [1], a simple calculation shows that even with a virtually unlimited supply of amino acids and enzymatic production of proteins, the odds of producing a biologically active protein are practically hopeless. So how much more hopeless is the situation where prebiotic conditions are taken into account?
-
The most basic problem is that the amino acids must be able to join together, by linking the carboxyl group of one amino acid to the amino group of the next to form what is called a peptide bond (Figure 3). But this is a condensation reaction (involving loss of water) so it will not occur readily in an aqueous environment (such as a primeval soup); and it is significantly endothermic (energetically unfavourable), so it will not occur at all without the input of energy. This is why, in the cell, enzymes are used to link peptide bond formation with the breaking of high-energy phosphate bonds so that the energy released in the latter can be used to enable the former.
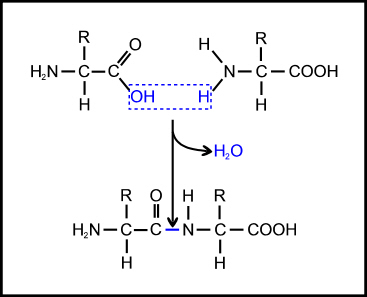
Figure 3. Formation of a peptide bond
-
But forming the peptide bonds is only half of the problem. Because any scenario to try to generate biologically active proteins would require a plentiful supply of amino acids (not the meagre yield found in soup experiments) and some means of trying out different amino acid sequences (to try to find one with biological activity). That is, there needs to be means for breaking peptide bonds, to separate the amino acids, and then recombining them in a different sequence.
-
Finally, in the discussion so far I assumed that only the desired peptide bond formation (i.e. between the carboxyl group of one amino acid with the amino group of the next) would take place under abiotic conditions. However, origin-of-life researchers are well aware that this is anything but the case: in reality, all sorts of undesired chemical reactions take place as well - mostly resulting in an ill-defined tar, rather than a polypeptide. Biologically, of course, enzymes ensure that only the desired peptide bond formation takes place.
So the few points mentioned above illustrate how a little thought readily exposes fatal flaws in the simplistic origin-of-life scenarios which are so often advanced in evolutionary texts.
RNA World?
Interest in the possible role of RNA as the earliest macromolecules arose in the 1980s when it was realised that RNA not only has an information-mediating role within cells (e.g. as mRNA and tRNA), but is also involved in carrying out catalytic functions. For example, RNA comprises about 60% of ribosomes and evidence emerged indicating that the RNA has a primary role in the synthesis of peptide bonds. (This is an intriguing facet of the chicken-and-egg relationship of proteins and nucleic acids, with each actually synthesizing the other.)
However, just as there are severe problems with an abiotic origin of polypeptides, similar issues apply to the production of polynucleotides, except that chemical considerations make the situation even worse.
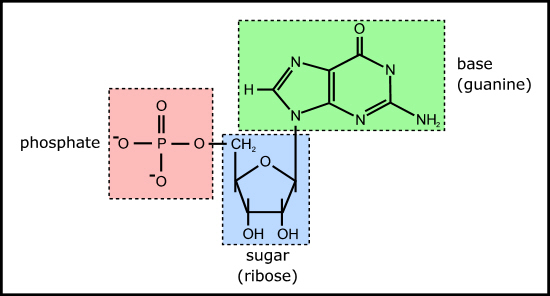
Figure 4. Example of a ribonucleotide - guanosine monophosphate
This is because the nucleotides themselves each comprise a base, sugar, and phosphate (Figure 4) which need to be joined together correctly - involving two endothermic condensation reactions (with all the problems that means) to make a nucleotide in addition to the endothermic condensation reaction involved in joining the nucleotides. In other words, compared with polypeptides, nucleotides are even harder to synthesise and easier to destroy; in fact, to date, there are no reports of nucleotides arising from inorganic compounds in primeval soup experiments.
The other extremely important issue is of course that, just as a polypeptide must be long enough and have the right sequence to be able to fold and have a useful biological function, the same is true of RNA.
Which brings us back to the key problem facing the origin of life: how did the information content of the protein and RNA sequences arise? Popular views would have us believe that it was through random production and association of amino acids and/or nucleotides; but we have seen that such an explanation is totally untenable.
Starting with a poor replicator doesn’t work
It is of course widely recognised that even basic replication systems as we know them are complex and could not possibly have arisen spontaneously. And the response to this is to assume (uncritically) that life could have got started with much simpler systems e.g. with short polymers which gradually improved their activity through the action of natural selection.
But there are some fundamental objections to this sort of scenario.
In other words, natural selection cannot take place until there is a reasonably reliable replicating system. So the first replicating system would need to have arisen exclusively by chance.
In other words, natural selection cannot take place until there is a reasonably reliable replicating system. So the first replicating system would need to have arisen exclusively by chance.
-
First, as mentioned above, a protein must be able to fold into a specific 3-dimensional shape in order to have biological activity. But the forces holding the folded protein in shape are so weak that many amino acids need to be involved - imposing a minimum length on their sequence of about 70[3], and maybe 50 for nucleic acids. So trying to improve the odds of finding a biologically active macromolecule by starting with short ones, just will not work.
-
A similar misperception is that the first replicator need only have had poor replicating ability, which could gradually have improved (by mutation and selection of improved versions). But it is important to note that a poor replicator is more likely to degrade through miscopying than to improve its performance, and this poses a dilemma for the production of a primitive replicator. Although the common presumption is that a crude replicator can gradually improve its performance through a natural selection sort of process, in fact there is a threshold before that could take place. That is, a replicator must already have a reasonably good performance in order to be able to improve on that performance.
Genetic code
Given that current biological systems are based on the interdependence of proteins and nucleic acids then, whichever might have come first - or even something different - at some stage a link would need to have arisen between them. This link now requires many biochemical components - involved in DNA replication, transcription and translation - and at the heart of it is the genetic code: the way in which triplets of nucleotides (called codons) in DNA specify amino acids in the resulting proteins (Figure 5).
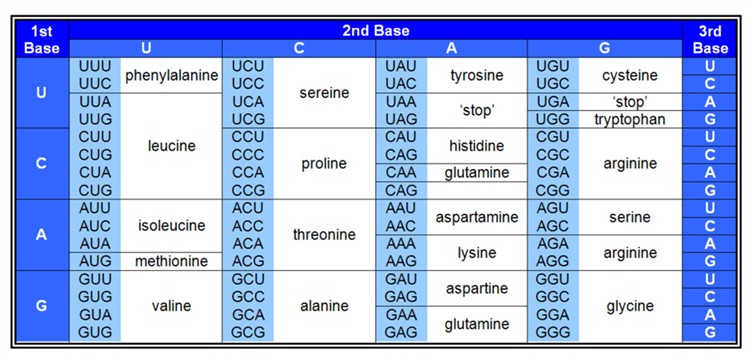
Figure 5. The Genetic Code
The origin of the genetic code is acknowledged to be a major hurdle in the origin of life, and I shall mention just one or two of the main problems. Calling it a ‘code’ can be misleading because of associating it with humanly invented codes which at their core usually involve some sort of pre-conceived algorithm; whereas the genetic code is implemented entirely mechanistically - through the action of biological macromolecules. This emphasises that, to have arisen naturally - e.g. through random mutation and natural selection - no forethought is allowed: all of the components would need to have arisen in an opportunistic manner.
Crucial role of the tRNA activating enzymes
To try to explain the source of the code various researchers have sought some sort of chemical affinity between amino acids and their corresponding codons. But this approach is misguided:
-
First of all, the code is mediated by tRNAs which carry the anti-codon (in the mRNA) rather than the codon itself (in the DNA). So, if the code were based on affinities between amino acids and anti-codons, it implies that the process of translation via transcription cannot have arisen as a second stage or improvement on a simpler direct system - the complex two-step process would need to have arisen right from the start.
-
Second, the amino acid has no role in identifying the tRNA or the codon (see Footnote). This association is done by an activating enzyme (see Figure 2) which attaches each amino acid to its appropriate tRNA (clearly requiring the enzyme to correctly identify both components). There are 20 different activating enzymes - one for each type of amino acid.
-
Interestingly, the end of the tRNA to which the amino acid attaches has the same nucleotide sequence for all amino acids - which constitutes a third reason.
Interest in the genetic code tends to focus on the role of the tRNAs, but as just indicated that is only one half of implementing the code. Just as important as the codon-anticodon pairing (between mRNA and tRNA) is the ability of each activating enzyme to bring together an amino acid with its appropriate tRNA. It is evident that implementation of the code requires two sets of intermediary molecules: the tRNAs which interact with the ribosomes and recognise the appropriate codon on mRNA, and the activating enzymes which attach the right amino acid to its tRNA. This is the sort of complexity that pervades biological systems, and which poses such a formidable challenge to an evolutionary explanation for its origin. It would be improbable enough if the code were implemented by only the tRNAs which have 70 to 80 nucleotides; but the equally crucial and complementary role of the activating enzymes, which are hundreds of amino acids long, excludes any realistic possibility that this sort of arrangement could have arisen opportunistically.
Progressive development of the genetic code is not realistic
In view of the many components involved in implementing the genetic code, origin-of-life researchers have tried to see how it might have arisen in a gradual, evolutionary, manner. For example, it is usually suggested that to begin with the code applied to only a few amino acids, which then gradually increased in number. But this sort of scenario encounters all sorts of difficulties with something as fundamental as the genetic code.
-
First, it would seem that the early codons need have used only two bases (which could code for up to 16 amino acids); but a subsequent change to three bases (to accommodate 20) would seriously disrupt the code. Recognising this difficulty, most researchers assume that the code used 3-base codons from the outset; which was remarkably fortuitous or implies some measure of foresight on the part of evolution (which, of course, is not allowed).
-
Much more serious are the implications for proteins based on a severely limited set of amino acids. In particular, if the code was limited to only a few amino acids, then it must be presumed that early activating enzymes comprised only that limited set of amino acids, and yet had the necessary level of specificity for reliable implementation of the code. There is no evidence of this; and subsequent reorganization of the enzymes as they made use of newly available amino acids would require highly improbable changes in their configuration. Similar limitations would apply to the protein components of the ribosomes which have an equally essential role in translation.
-
Further, tRNAs tend to have atypical bases which are synthesized in the usual way but subsequently modified. These modifications are carried out by enzymes, so these enzymes too would need to have started life based on a limited number of amino acids; or it has to be assumed that these modifications are later refinements - even though they appear to be necessary for reliable implementation of the code.
-
Finally, what is going to motivate the addition of new amino acids to the genetic code? They would have little if any utility until incorporated into proteins - but that will not happen until they are included in the genetic code. So the new amino acids must be synthesised and somehow incorporated into useful proteins (by enzymes that lack them), and all of the necessary machinery for including them in the code (dedicated tRNAs and activating enzymes) put in place – and all done opportunistically! Totally incredible!
In view of these fundamental and insurmountable problems, it is no wonder that more than half a century after Miller’s first experiments, rather than solving the riddle of life’s origin, researchers have become far more aware of the difficulties. Yet the belief persists - or at least is promulgated - that life arose in a naturalistic way. It certainly seems that this view is based far more on commitment to a naturalistic ideology than on empirical science.
Footnote:
This can be seen from an experiment in which the amino acid cysteine was bound to its appropriate tRNA in the normal way - using the relevant activating enzyme, and then it was chemically modified to alanine. When the altered aminoacyl-tRNA was used in an in vitro protein synthesizing system (including mRNA, ribosomes etc.), the resulting polypeptide contained alanine (instead of the usual cysteine) corresponding to wherever the codon UGU occurred in the mRNA. This clearly shows that it is the tRNA alone (with no role for the amino acid) with its appropriate anticodon that matches the codon on the mRNA.
References
[1] Axe D, Estimating the prevalence of protein sequences adopting functional enzyme folds, in J. Mol. Biol., 2004 Aug 27; 341(5):1295-315.
[2] Horgan J, The End of Science, Little, Brown & Company, 1996.
[3] Kyte J, Structure in protein chemistry, Garland Publishing, 1995, p243.
[4] Popper K R, Scientific reduction and the essential incompleteness of all science, Ch 16 in Studies in the philosophy of biology, Eds Ayala and Dobzhansky, University of California Press, 1974.
Image credits:
Thumbnail - NASA - public domain
All article images - © The author